Having a successful discovery project is not easy, as a matter of fact, it is one of the most challenging areas of ITOM to “get right”. ServiceNow Discovery serves as one of the main tools to create a reliable data layer used in other processes. Through using discovery organizations get their meta-data, cloud/PaaS & infrastructure in order. Yet how come so many organizations fail in this endeavor? In this article we deep-dive into the most critical areas to succeed with ServiceNow Discovery.
The three strategic pillars of discovery
Discovery typically comes as an exercise for the entire enterprise and leadership team. We have chosen to categorize the different topics into three strategic pillars through our Einar & Partners experience. Each pillar is of equal importance yet many customers, enterprises, and experts focus on just a few. As the old cliché goes, sometimes one can’t see the forest from the tree’s.
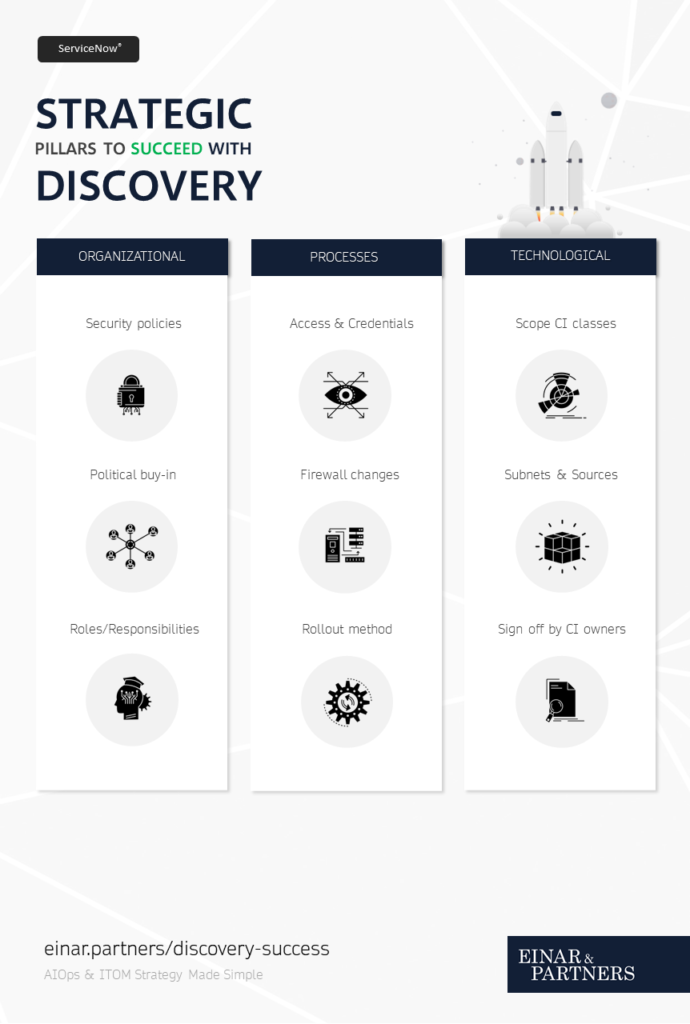
Organizational
The perhaps most important pillar is the organizational one. Discovery is not so much a technical exercise as it is organizational. Based on our experience, over 80% of failed discovery projects fails due to neglect in this area.
Security Policies
Security and discovery go hand-in-hand. It is of critical importance to align with the security team at an early stage. This is especially common if you are an organization with a lot of legacy IT. Exposing your entire infrastructure inventory in the cloud can be sensitive. Then there’s also the questions about credentials, encryption, security and access. Failure to involve the security team early might cause unpleasant discussions at best and a complete stop of the project at worst.
Political buy-in
Political buy-in does not necessarily mean the management team, although that’s also important. It’s more about finding champions within the organization that can work as diplomats. If you do not already use a discovery tool or have a CMDB, there’s a large probability that it will become a politically sensitive topic. Why? You might ask. Job security is the answer based on our experience.
When introducing a discovery tool people fear their relevancy and role. Silo’s of data is often a thinly hidden veil of a firm’s internal boundaries. Different departments within a company, afraid of relinquishing power, are loth to share their data or change what they collect and how. There for getting the political influencers and buy-in is extremely critical and one of the more difficult tasks.
Roles & Responsibilities
Expecting a successful discovery project? Then expect to allocate budget for some new roles and responsibilities. Failure to do so results in little to no accountability and frustration from co-workers who suddenly are expected to help without formal approval. Setting expectations towards the organization, assigning the right roles and who is in the driver seat is a must.
Processes
Having solid processes are critical to succeed with discovery. After all, we’re trying to coordinate potentially hundreds of data sources and stakeholders into one data lake at the end of the day. Not streamlining the processes regarding how to execute is dangerous. Thinking one can do things “ad-hoc” as the need arises? A critical mistake too many organizations fall victim to.
Access & Credentials
Tightly aligned with the security policies and team, this is one of the more critical pieces. How will credentials be created, facilitated and stored for discovery? When a new system or source is connected so must the credentials be. Following a rigid process for handling of credentials regarding discovery is a critical puzzle piece.
Firewall changes
When working with discovery there is a need to allow access and open firewalls. Some organizations have a very fragmented network or have strict segmentation. Relying on a process for how to maintain firewall openings suddenly becomes very important. The right ports, the right subnets and the right protocols must be documented and managed. Without it you’re running into the risk of constant errors, access issues and long lead-times to get a successful discovery going.
Rollout method
We’ve seen discovery projects complete in two months and we’ve seen them finish in two years. It all depends on the rollout method and how you plan around it. When rolling out discovery it can be done in many different ways. Yet one common factor is the coordination between different teams and sign-off by CI owners. Choose the right rollout method and stick to the planning.
Technological
The last pillar of the discovery strategy is to get your house in order from a technological perspective. Neglecting this part might lead to a successful discovery project but without anybody using the data or caring about it.
Scoping CI Classes
One of the first and most crucial step is to scope the appropriate CI classes. Meaning, what do we want discovery to discover for us? This determines which key stakeholders to involve. Who investigates and inspect the data, and who uses it? Having a clear scope of CI classes to include, preferably in a stepped approach is our recommendation.
Subnets and sources
Once CI classes are scoped it’s time to dig deeper into the different network segments and sources. Where is the data residing and how to we access it? Where are the credentials stored and how can we optimize the discovery schedules? If you are a global company with data centers spread across the world, multiple clouds and local differences, this exercise tends to be the most time-consuming. Optimize the discovery for which networks and sources to target (and when) ensures stability and consistency.
Sign off by CI owners
Different CI owners also have different requirements. Some owners might be concerned on the impact of the network. Others on the impact on CPU & Load. Meanwhile the third team might be worried about the data quality and individual attributes. In other words, it’s essential to have a governance process for CMDB and to have CI owners inspect and sign off discovery results. This way they also feel more connected to the project and are more likely to use the data.
Conclusion – making discovery successful
As we can see, there are many elements to a discovery rollout that need to be in place for success. The one’s mentioned above are just a few with many more puzzle pieces in the equation. More than anything it is indeed an exercise of politics, coordination and careful planning. Spending adequate time in the preparation phase is key to having a long-lasting discovery success. At Einar & Partners we recognize these elements and the sensitivity of each area. We therefore hope that our readers and clients will find this quick-guide useful moving forward in their discovery adventures. And as always, we’re here to help.