Starting Q2 in 2022, Einar & Partners are happy to announce that we’re officially launching our Luxembourg office to innovate with customers- and partners in the French- and German speaking markets of EU. With a long track record of success in ITOM transformations, the new office aims to bring market leading expertise in ITOM- & AIOps. Both in- and outside of Luxembourg.
Targeting new markets- & verticals
According to many professionals, Luxembourg is the beating heart of finance in Europe boasting major banks and active innovators. With local expertise around regulations and data security, the office of Einar & Partners will serve a wider base of customers and companies in the finance sector of Luxembourg. Additionally, the expansion into Luxembourg will act as the delivery-center for the offerings of Einar & Partners in the French- and German speaking parts of Europe.
Officially founded in October 2020, Einar & Partners have seen major successes in the areas of AIOps- & ITOM already. With a deep commitment to engage with the ITOM community, as well as the formation of strategic partnerships and alliances, Einar & Partners have experienced an impressive growth trajectory.
Michel Conter, the local managing partner at Einar & Partners Luxembourg, explains:
“With a rock-solid reputation in the ServiceNow community, and our pin-pointed focus on ITOM strategy, we’re excited to expand into new regions and verticals from Luxembourg. Having already worked on some of the largest ITOM transformations in the greater region, we believe our local presence will make a big difference.”
AI Operations + Luxembourg is the perfect combo
The Grand Duchy is the gateway of choice to the European market, and the country is hosting more than 350 active start-ups within FinTech, IT and AI – as well as over 15 incubators. For Einar & Partners, who is also involved in ITOM for public sector as well as finance, the Luxembourg launch makes perfect sense.
The aim of Einar & Partners Luxembourg is to grow rapidly the coming next 2 years and refine our offerings especially in the verticals of Finance and Public Sector. With experience having worked with some of the largest banks already in EU, as well as with public sector in Sweden and Norway, the expansion into Luxembourg constitutes the next step.
Read more about the Einar & Partners Luxembourg by visiting our new about page.
Starting Q4 2021, Einar & Partners are unveiling a unique research unit focused on the industry of AIOps with special attention on the ServiceNow ecosystem. According to valuate reports market research, the global AIOps Market size is projected to reach USD 23.9 Billion by 2027, from USD 4.0 Billion in 2020, at a CAGR of 30% during 2021-2027.
Bringing transparency to promises of ROI
AIOps is a fairly new terminology coined by Gartner in 2017, and with such a significant new market also comes big promises. Today, many decision-makers and IT leaders ask themselves if AIOps truly gives return on investment, if the products are mature enough, and what is the impact of implementing AIOps across the IT org?
Vendors have many promises of what AIOps can do—such as lower time-to-resolution for incidents, improving service quality, faster root cause analysis, and ultimately decreasing outages. Yet, the cost for implementing AIOps across an IT org is high, and the time-to-value is not always clear.
The Einar & Partners research unit focuses on independently researching the impact of AIOps on IT and the business. The research unit will verify and measure ROI, common challenges, time-to-value, implementation timelines and other important variables when considering an AIOps project.
Behind the research unit are leading industry experts in AIOps as well as volunteers.
Akif Baser, the new R&D Lead at Einar & Partners, explains:
“We are currently developing methodologies for data measuring, collection and presentation. Our research unit aims to provide industry-leading data that decision-makers directly can use as a basis for their AIOps budget- & project decisions.”“On a long-term basis, we aim to connect academic institutions in the Netherlands to assist in analyzing market trends and new innovative ways AIOps can help.” – Akif adds.
ServiceNow Benchmarks, Reports & Applied Research for ITOM & AIOps
One of the key players in the AIOps market is ServiceNow. With multiple acquisitions done in the past 24 months, such as Loom systems and Lightstep, the platform is on a trajectory to become one of the leading vendors for AIOps.
ServiceNow today has a strong IT Operations portfolio, namely their famous ITOM suite (IT Operations Management). The company is projected to hit a subscription revenue of 15B$ within the next five years – of which ITOM & AIOps is a significant piece.
The Einar & Partners research unit will be among the first research bodies that divert special attention to the ServiceNow ITOM & AIOps ecosystem. The goal is to provide the market with benchmarks, analysis, strategic workshops and in-depth content around ServiceNow ITOM & AIOps.
“Our content has already received an enormously positive response in the ServiceNow space, and now we want to take our material around ITOM to an even higher level.” – Says Alexander Ljungström, founder of Einar & Partners.
Read more about the Einar & Partners research unit by visiting our new research website.
The release notes of the latest ServiceNow version is out in public and this time we’re going all the way to Rome. The new release is packed with improvements, additions and developments in the ITOM parts of the platform. In this article by Einar & Partners we give you all the important highlights and news in ServiceNow ITOM for the Rome release.
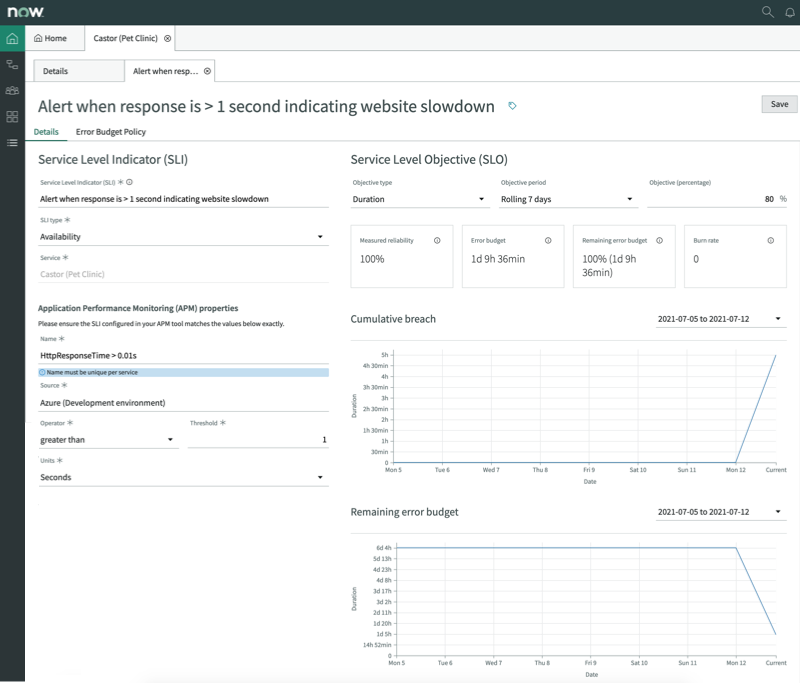
Site Reliability Metrics for SRE’s and Ops
Site Reliability Operations, or SRO – is a product by ServiceNow created specifically for SRE teams that are working heavily with microservices and site reliability engineering. In the Rome Release, the SRO product is being improved additionally with Site Reliability Metrics. Engineers and operations teams that are working with site reliability engineering can now see performance, error budgets, indicators and service level objectives. All within one workspace.
This is a welcome addition to the previously rather lightweight SRO application. It also demonstrates that ServiceNow is more serious than ever to develop their positioning towards cutting edge DevOps and containerized practices.
Containerized MID-servers
Speaking of containerized practices, the MID-server is now officially put into a docker image and available to be pushed out as a container based application. This has already existed for a while, although not supported officially by ServiceNow – until now that is. In practice this means that the MID server capacity and sizing can be scaled and sized very easily depending on load and anticipated activity (for example, discovery).
At the time of this article being written, IntegrationHub and Orchestration is not (officially) supported when using containerized MID-server docker images.
Agent Client Collector – agent based discovery
The agent client collector (ACC) is officially released in its full capacity in Rome, and is starting to become quite the mature alternative to agentless discovery. The agent based discovery in ServiceNow solves the long-standing challenge of having to provide credentials and opening firewalls across the infrastructure. When using the agent based discovery, customers should still be aware that products such as service mapping is not yet supported.
Nonetheless, agent based discovery is perfectly suited for endpoints, laptops and infrastructure where agentless discovery is not permitted.
For more information about the ACC-V framework, check out our video below.
More sources for Health Log Analytics
Health Log Analytics, originating from the acquisition of Loom Systems roughly 2 years ago, has now matured to a strong core-piece of the ServiceNow AIOps portfolio. In the latest release the Health Log Analytics product supports a whole bunch of new sources for ingesting log data, such as:
Amazon CloudWatch
Amazon S3
Microsoft Azure Log Analytics
Microsoft Azure Event Hubs
Apache Kafka
REST API, for streaming your log data to the instance in JSON format
Event Management news
For Event Management it is now possible to integrate Grafana events out of the box and plugin directly to the Event Management engine in ServiceNow. Additionally, ServiceNow has added support for EIF format (Event Integration Facility). It might sounds obscure, but this format is the de-facto standard format for a lot of IBM products. With the closer relationship between ServiceNow and IBM, this will save a lot of headache when integrating technologies such as IBM Tivoli and the corresponding monitoring agents.
Oracle Cloud Discovery – official support
Oracle Cloud can now fully be discovered by ServiceNow Cloud Discovery. Previously only available as an app to the ServiceNow App store, it is now fully integrated in the core part of Discovery. This means that cloud resources that customers have in oracle cloud can now be real-time refreshed and included in the CMDB with a very simple connection.
Kubernetes and cloud components in Service Maps
For organizations that are using tag based service mapping, the latest release will make a big difference. Previously every resource that needed to show up in a tag-based service map also needed a tag. Although this principle makes sense from a logical standpoint, in containerized environments, not every pod and component is tagged.
In the Rome release Kubernetes and cloud components can now be automatically be included based on their relationships. In other words, you just need to have the parent tagged in order to include children.
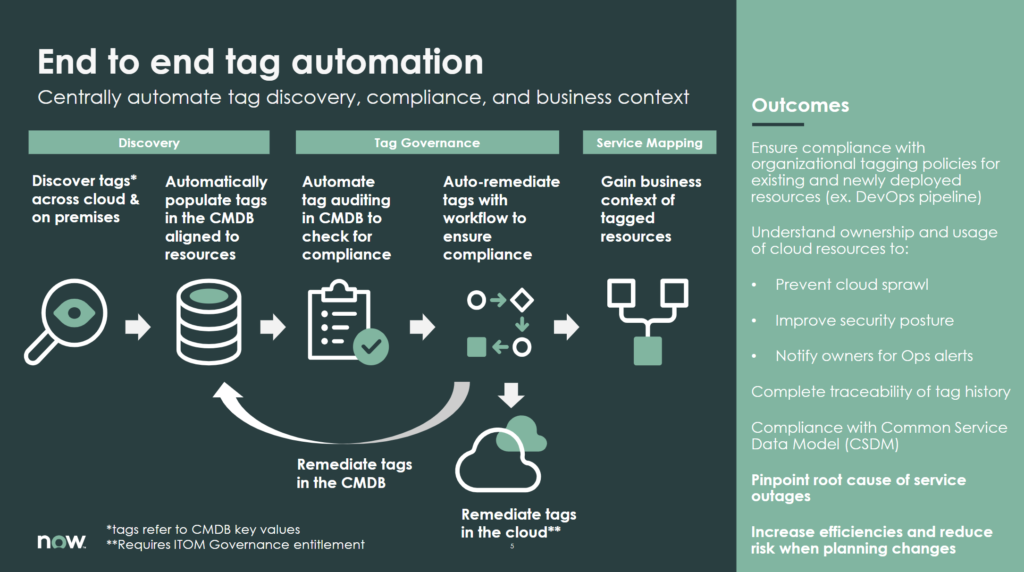
Tag Governance – a new application
Keeping track of tags in ServiceNow have already been possible for a few releases. But with the latest release, the capability have been lifted to entirely new levels. This is perhaps the most exciting product in the Rome release in our opinion.
With the new tag governance application, tags can be tracked, certified and kept up-to-date through workflows and rulesets. But perhaps more importantly, any tags that are found not be compliant with the defined rules can be remediated. In other words, ServiceNow can correct tags in Azure, AWS and other cloud platforms.
A single pane of glass to keep track for the tagging across multiple clouds and applying smart workflow logic. Isn’t that what we love about this platform?
As we can see each release continues to be packed with additions to the ITOM portfolio. It appears like ServiceNow is pushing with full force towards keeping control, visibility and compliance on cloud resources and modern architectures (containers, serverless).
Additionally, in the latest release we also see evidence of just how serious ServiceNow are about bridging in to the space of observability and site reliability engineering. With the recent acquisition of Lightstep, a DevOps observability platform, ServiceNow chooses to strategically position themselves towards the modern era of IT Operations more and more.
Einar & Partners have entered a partnership with The Cloud People, a ServiceNow- & Google partner based in the Nordics. The partnership will strengthen the mutual cooperation between the companies in the areas of modern IT Operations powered by Machine Learning & AI.
The Cloud People – Smart Resourcing
The Cloud People approaches projects and engagement through a new method of “smart resourcing” for consulting – leading to the right skills getting involved at the right time. The methodology aligns well with the philosophy of Einar & Partners, where we believe in pinpointed and target efforts as a good substitute for more traditional implementations.
ITOM Expertise to the Nordic market
The partnership’s goal is to expose Einar & Partners resources (with their unique industry insight and experience in ITOps) towards the eco-system of The Cloud People.
The IT landscape is growing more complex, with IT shifting more workloads to the cloud and experiencing a surge in modern DevOps practices. As a result, the demand for strategies that reduce complexity is massive, with machine learning & AI knocking on the doorstep.
This is where Einar & Partners meet with The Cloud People, providing A+ ServiceNow ITOM resources to companies who want to simplify the nature of their ITOps.
Below are some comments from the leadership team.
“We’re thrilled to expose our expertise to the network of The Cloud People. But perhaps more importantly, we feel there’s fundamentally a strong common ground between how projects should be delivered, with a no-fuzz approach and full transparency. It will be an exciting future, that’s for sure.”
Alexander Ljungström, Managing Director @ E&P
“The Cloud People are all about finding the right talent for the right job. With the partnership of Einar & Partners, we are taking our ServiceNow ITOM skills and capabilities to a whole new level. We look forward to working with Einar & Partners team to bring added value to our customers around the world.”
Hannes Hirvikallio, Director & Advisor @ The Cloud People
More Information:
The Cloud People A.S Rådhusgata 5, 0151 Oslo, Norway +47 23 29 23 00 info@thecloudpeople.com
Welcome to our second masterclass about creating real value from the ITOM portfolio in ServiceNow. This particular masterclass will cover service mapping and the factors to consider for creating a successful rollout.
The ultimate end-goal for any Service Mapping project is to map infrastructure to the application layer automatically. However, there are many pitfalls, especially in a dynamic and DevOps-driven world of cloud and infrastructure.
Based on over 15 Service Mapping implementations and rich practical experience, industry-leading experts will share their lessons. In this fast-paced webinar by Einar & Partners and iTSM Group, we will cut to the chase of the strategies that work and what does not.
The webinar is aimed for decision-makers, experienced consultants, and platform owners who are planning to rollout Service Mapping in ServiceNow. During the one-hour session, listeners will find out about the organizational- & budget aspects for success, the technical hurdles to overcome, and proven models to formulate a rollout plan for Service Mapping.
Pre-requisites?
We assume any attendees are already familiarized with the concept of ServiceNow discovery and what it does. If not click here to read more.
Presenters
Alexander Ljungström, who previously worked at ServiceNow in the Service Mapping team and Fabian Kunzke, ITOM- & AIOps lead (iTSM Group), will disclose their knowledge without any sales-fuzz or reiterating product documentation.
Alexander Ljungstrom, Managing Director & ITOM enthusiast @ Einar & Partners.
“Having previously worked in the ITOM team at ServiceNow, leading the ITOM BU at Fujitsu and now days the forefront at Einar & Partners – Alexander have helped over 40 organizations transformed with ITOM & the ServiceNow platform.”
Fabian Kunzke, AIOps & ITOM Lead @ iTSM Group
“Fabian is the AIOps & ITOM lead at iTSM Group. With great technical experience in multiple large-sized ITOM rollouts, and avid community contributor, he gives a strong innovative and sharp technical view on the ITOM journey. “
The Quebec version of ServiceNow was recently released to the general public and available for upgrade to customers. For ITOM- & AIOps enthusiasts in the industry, the new release is packed with exciting new additions and completely new product offerings from ServiceNow. It was a long time ago so many updates were added to ITOM and we’re very excited about what new innovation it will bring. To get people up to speed, we’ve compelled this deep-dive article of the 10 most significant and essential ITOM updates in Quebec.
Loom becomes Health Log Analytics – machine learning for log-data
Approximately a year ago, ServiceNow acquired Loom Systems. The company produces a platform which can detect, analyze and act on anomalies in log data across the IT landscape. As we all know, today’s dynamic IT infrastructure generates huge amount of logging. As a matter of fact, logs are the primary tool for SRE’s and engineers during root cause analysis and troubleshooting.
One year later and we can witness Loom System for the first time integrated as a native product in ServiceNow ITOM platform. The new product is called “Health Log Analytics” and it ties directly into the ITOM Health part of ServiceNow (event management & machine learning).
This is a potential game-changer in the ServiceNow AIOps portfolio. Customers can connect to Elasticsearch, Splunk and many more tools to start ingesting log-data to ServiceNow in realtime. With the proprietary and powerful machine learning algorithms that the platform provides, ITOps teams can see anomalies, trends, and log-data patterns at the tip of their fingers.
Traditional metrics are becoming more outdated and with the explosion of DevOps and containerized environments, log-data is more critical than ever before. We can already now start seeing synergies between the Agent Client Collector for monitoring logs and Heath Log Analytics .
For a quick overview of Health Log Analytics, see the video below by ServiceNow.
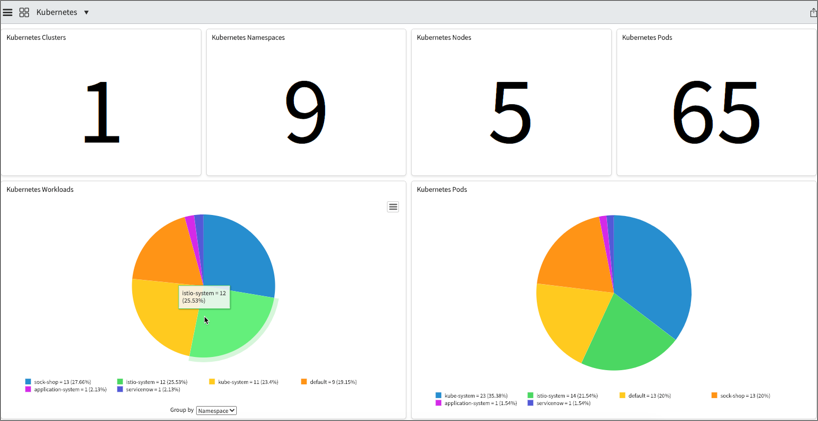
Kubernetes Discovery Improvements
Kubernetes and containerized environments are more and more important. In the latest Quebec release, customers have the ability to track the YAML files for Kubernetes configurations. By tracking the configuration files, you essentially audit the YAML setup for Kubernetes which is very powerful in troubleshooting scenarios. Additionally, customers who are relying on Istio service mesh can also discover the service mesh fully.
Site Reliability Operations – Track your microservices
Speaking of microservices, in the past months ServiceNow has deployed an excellent app to their app-store for registering and tracking microservices. Through the “Site Reliability Operations” free application, developers can easily register microservices in ServiceNow. Additionally, it has an API that can be hooked into CI/CD pipelines to keep microservices up-to-date. Integrated with Event Management and lifecycle workflows, the application is an excellent way to bridge DevOps into IT Operations.
Changes to licensing model (node counting)
In Quebec PaaS-managed virtual machines and desktops are no longer counted towards the licensing cost. To quote ServiceNow:
“You can identify virtual machines (VMs) that are used as desktops (such as VMware VDI) or managed automatically by PaaS (such as AWS EC2 Container Service). You can exclude VMs from the Server Licensed Resource category.”
ServiceNow Documentation – Quebec Release
Machine Learning in Service Mapping
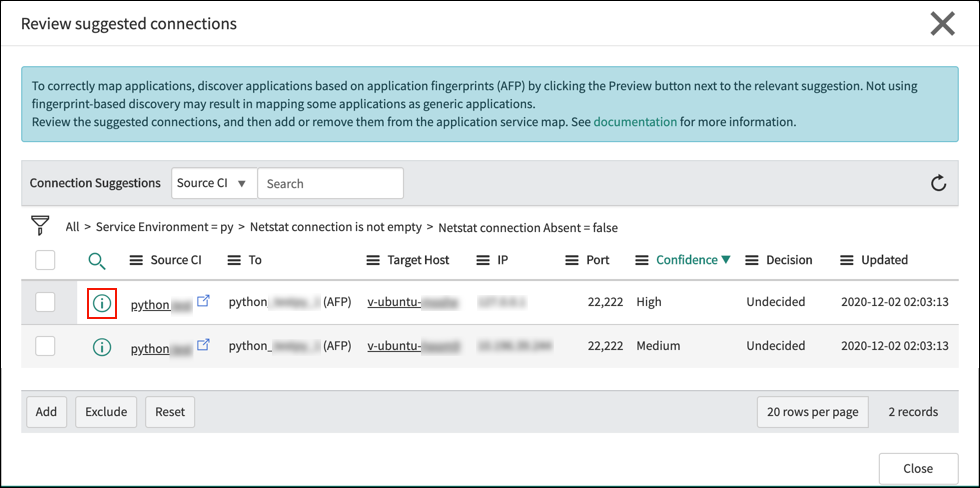
When running traffic-based service mapping, ServiceNow will automatically track TCP traffic occurrence and frequency and apply machine learning to the dataset. Over time the platform will learn what likely candidates should be included in Service Mapping, their role, their function and give “connection suggestions”. For companies that run application stacks with a lot of incoming and outgoing traffic, this is an excellent way to discover “shadow-dependencies”.
ServiceNow will try to categorize if connections and CI’s have one of the following functions:
Central: Connection used by the entire organization. For example, SSO.
Observer: Likely an application deployed in many places of the infrastructure. For example, monitoring agents.
Middleware: The connection is a middleware component that exchanges data between multiple services.
Internal: A connection only occurring for a particular application service.
Audit MID-server calls for increased security insights
MID-server calls, such as WMI, SSH or WinRM are now audited in a structured way. Discovery administrators can now easily see what machines have recently received remote calls, status, timestamp and trigger. This is a small but important feature that will be highly relevant for a lot of security teams.
Credential aliases – pinning credentials to discovery
Speaking of security, credential aliases can now be used in discovery. For readers who are unfamiliar with this concept, it used to only exist in orchestration, whereas you can “pin” credentials to activities. Now you can use this functionality for discovery, which is a big improvement from a security standpoint. Administrators and the security team can lock credentials on an even more granular level to apply for specific discovery schedules.
Help the helpdesk gone
The good and old-school “Help the helpdesk”-script came into existence before the discovery product. It’s one of the oldest relics in the ITOM suite and has been a faithful companion for many, many releases. But like with many stories, all good things come to an end. The script, which was reasonably outdated by this point, has now been deprecated.
What will replace it? Most likely the agent client collector with agent-based discovery in the future.
IntegrationHub updates
For those who love the flowdesigner, IntegrationHub has been updated with some serious goodies. If you’re an old-school workflow-guru, you will remember the “scratchpad” variables. This is now also a feature in flow designer. Additionally, from an ITOM perspective, you can now write direct SQL queries through JDBC and transfer files through SFTP.
New Linux installer for MID-servers
The Linux installer for MID-servers has received an extensive upgrade in cosmetics and user-friendliness. The new installer guides users through a user-friendly manner during installations to ensure that system requirements are met accordingly.
Summary
As we can see, the new Quebec release is absolutely packed with a lot of new innovative features, especially related to machine learning, algorithms and anomaly detection. We’re especially excited about the improvements in Service Mapping for traffic-based connections as well as the new fantastic Health Log Analytics addition. An exciting future and year head!
What do you think is the most exciting feature? Let us know in the comments below.
At the beginning of February 2021, Einar & Partners hosted a webinar with iTSM Group about the factors to consider when moving beyond discovery in ServiceNow ITOM. Many organizations that purchase ServiceNow find themselves stuck in moving beyond the basic CMDB and ITSM setup.
This article is an in-depth report by Einar & Partners on how to move away from stagnation to harvest the benefits of IT Operations Management.
Welcome to our deep-dive about creating the ultimate ServiceNow ITOM Roadmap after Discovery.
Before we get started – let’s define a roadmap
When approaching ITOM transformations in the industry, one will often find that a roadmap is drafted and created based on the available ServiceNow ITOM modules, or sometimes – the licensing model.
Such as ITOM Visibility, Health & Insights.
Although this approach is not wrong, we argue that it does not constitute a roadmap per se, but rather a module- or license ramp-up model.
In other words, a roadmap should not be driven by when functionality is enabled, but by the needs of the organization (and therein lies the priorities).
Ultimately the ITOM modules or licensing ramp-up should come as a result of a planned roadmap – not the other way around.
To give a practical example, think of the difference “In 6 months, IT should be doing automatic impact analysis” compared to “In 6 months we are going to activate licenses for Service Mapping”.
The former is the driver, the latter is the result.
Simplifying the ITOM portfolio
Perhaps you are a decision-maker who is planning for ServiceNow ITOM, or perhaps you are a consultant that finds yourself embarking on the ITOM journey advising a client. Regardless of your job or purpose for being interested in an ITOM roadmap – let’s try to first simplify the ITOM portfolio.
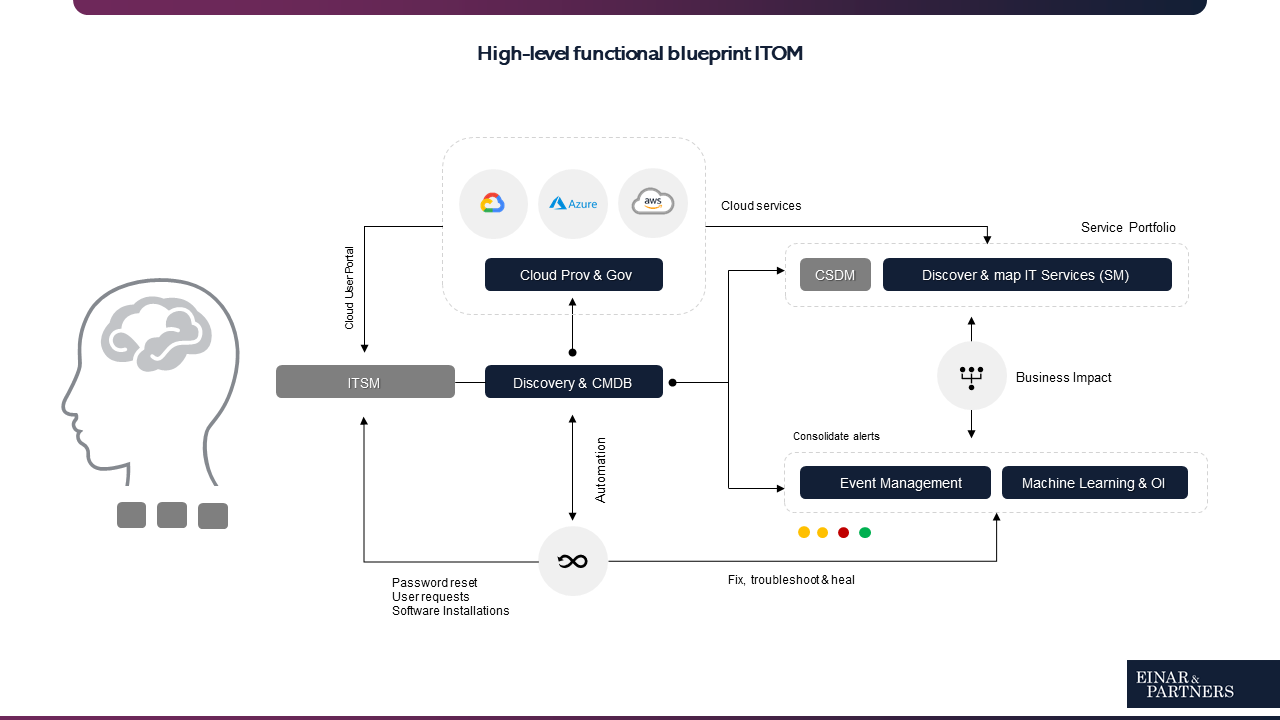
Have a look at the blueprint below. As you can see there are many modules to take into consideration (click on the images for larger size).
To make things simple, regardless of which modules we are interested in – the road we take after discovery can generally be categorized in one of two areas; Business- or IT Innovation.
In this article, we will cover the first area of business innovation. One assumption before we continue is that your organization already is using ITSM and have a basic CMDB coming from ServiceNow Discovery.
Business innovation in ServiceNow – what’s that?
Business innovation might sound like a fuzzy concept made out of buzzwords, so let’s debunk what it means in the context of ServiceNow ITOM. With business innovation the primary benefits are:
Moving to a service-minded mindset as an organization – defining service portfolio, mapping IT services and application portfolio management. The framework encompasses everything from enterprise architects to service owners, application owners, IT staff & end-users.
The ability to measure, report and benchmark business KPI’s
Internal billing & cost calculations
Accurate and up-to-date mapping of IT services and what role infrastructure play in the bigger picture
Business innovation aims to have clear definitions of what services an organization provides to internal- and external users. Thanks to a service-oriented definition throughout the organization, internal billing, support, reporting & impact analysis can be made a reality (as a few examples).
In the ServiceNow ITOM language this means getting started with CSDM tightly followed by Service Mapping (to map IT services).
Avoiding budget overspend for CSDM & Service Mapping
Starting with CSDM (common service data model) and Service Mapping is an organizational effort more than anything else. As the ServiceNow team embarks on the journey to implement an application- & service portfolio, pretty much the entire organization will be involved in one capacity or another.
The bulk of the effort is coordinating between different stakeholders. Such as service owners, application owners, enterprise architects, process owners, technical staff, and the support organization. With the end-goal of defining the service- & application portfolio (including IT services).
Many organizations find this journey overwhelming and hire expensive consultants to do the work for them, but the reality is that the determining success factor is an organization’s involvement and ability to bring together, prioritize and agree upon definitions more than anything.
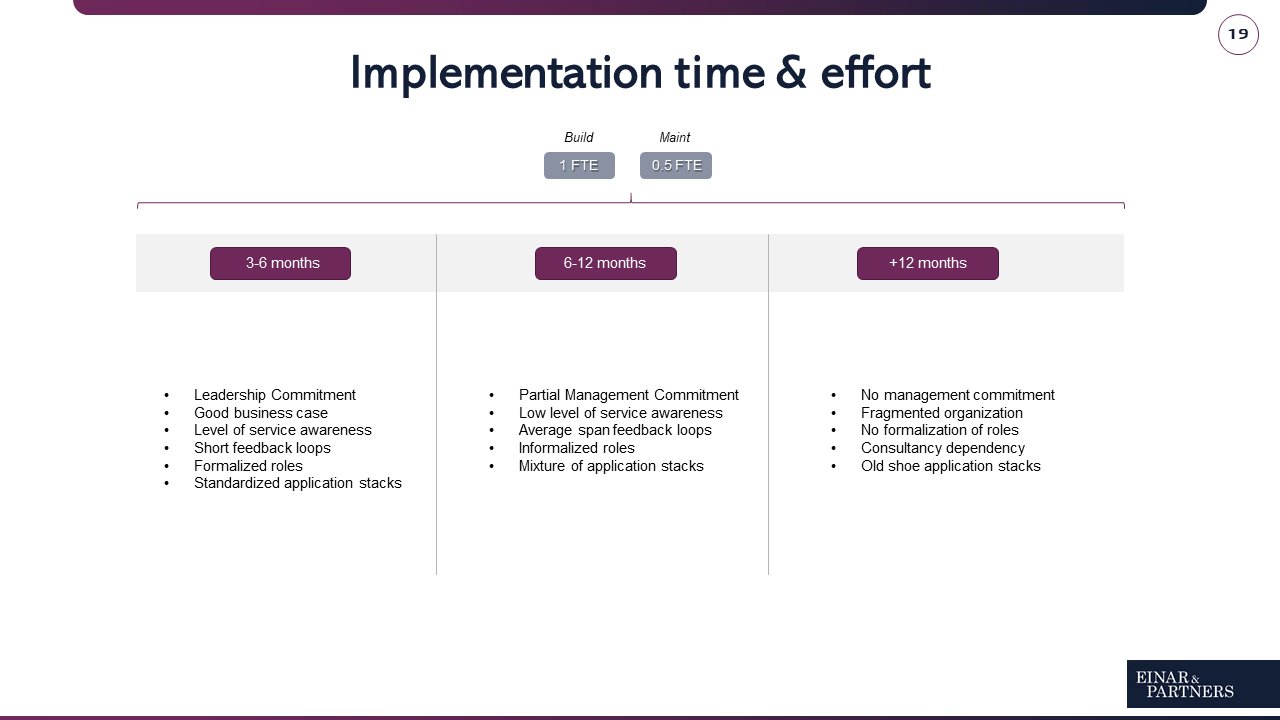
Average implementation time
When starting with CSDM and service mapping to build a portfolio, the time to completion might vary greatly depending on several variables (like with any project). It is essential to understand that CSDM and Service Mapping is an ongoing journey with no real end-date as such, but merely different milestones. It is expected that elements will change, iterate and be refined upon over time.
The main factor determining the implementation time and budget is the organization’s existing maturity of service awareness. An organization that already has a certain degree of “service-minded” definitions, albeit informal, will have a more comfortable journey than a fragmented organization that starts from a large legacy.
See example below:
Notice how the size of the organization necessary isn’t a variable, or play a big part. Global organizations of thousands of employees can be quicker than small regional organizations if the conditions are right.
Build- & maintaining CSDM & Service Mapping
During the build phase of “Business Innovation” typically 1 FTE is required. The primary work of this person would be to map IT services with Service Mapping. Most of the time the FTE translated to a Service Mapping Specialist familiar with the product.
There’s also an internal investment spent with agreeing on services & definitions from a broader perspective. During the maintenance phase of Service Mapping, the ongoing up-keep typically translates to 0.5 FTE.
We recommend training an in-house resource for maintaining Service Mapping and formalize the role (Service Mapping Specialist).
The cost of implementing CSDM & Service Mapping
With the right approach, consultancy companies should be engaged on a strategic “need for”-basis. For example, the initial efforts of mapping services and assisting with framework/governance structure for CSDM. Too many organizations fall into the pitfall of having consultants start to finish when it comes to CSDM. If the conditions are right, with good coordination and buy-in from leadership – consultants can be used smartly.
The majority of the budget allocation is an organization’s internal effort when defining services and engaging infrastructure teams for mapping the IT services. The cost of configuration and development is neglectable in the grand scheme of things.
Keep in mind that to utilize Service Mapping discovery must first be in place (providing a basic CMDB).
Licensing cost
From a ServiceNow licensing perspective the ITOM package called “ITOM Visibility” is the more strategic choice for most organizations, as it includes a bundle of both Discovery- & Service Mapping licenses. The rest of CSDM comes without licensing costs as it is part of the normal CMDB.
Tip: Consider combining ITOM modules for better “deals” at ServiceNow
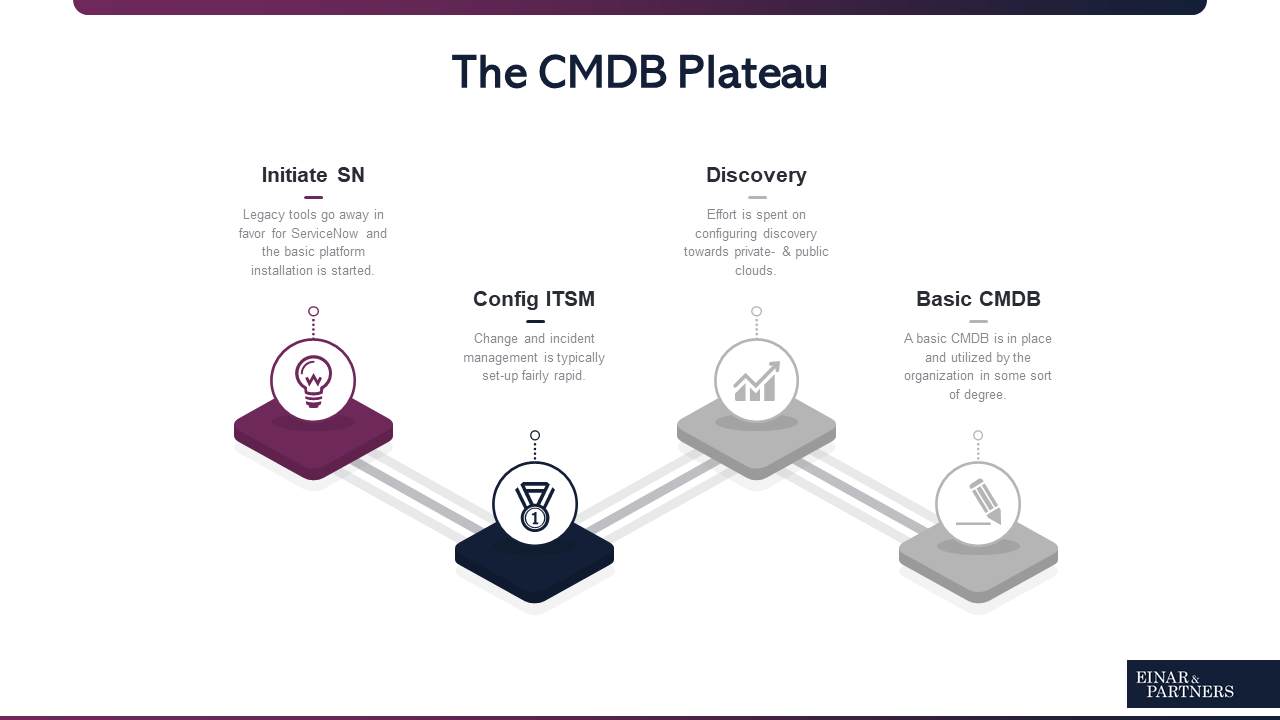
Many organizations stuck on the CMDB plateau
We meet some clients and organizations who feel “stuck” on the basic ITSM with some discovery data in place. Often the question is how to proceed and if it pay’s off to start with CSDM & Service Mapping.
Below we can see an example of the most common setup driving the need for change.
To get “out of the CMDB plateau”, we suggest following the previously mentioned tips- & recommendations. They are summarized below.
Simplify the priorities and try categorizing them according to business- or IT innovation
For business innovation (CSDM & Service Mapping) the majority of the effort will be an internal one
Agreeing on definitions and how to describe services tend to engage multiple different teams and require much input
The maturity of where the organization already are in regards to service-oriented thinking will also determine the timeline
The most important factor is the ability to coordinate, tightly followed by leadership buy-in
Ultimately, embarking on a journey of CSDM is a cultural shift in mindset. The goal is to have the business & IT agreeing upon a standard method for describing the services they provide in the organization.
Next steps from here
Our next article will dive into the “IT Innovation” part and how it relates to business innovation. We recommend our readers to familiarize themselves with the topic by watching our webinar below about ITOM roadmaps (on-demand).
Any questions? Feel free to contact us without any strings attached.
Einar & Partners have entered an exclusive agreement with the innovative and upcoming AIOps vendor AIMS Innovation. AIMS Innovation, based out of Norway, provides the market with a unique AIOps platform. The platform aims to cut implementation time and costs for enterprises and companies wanting to get started with anomaly detection and AIOps.
AIMS – The quickest way to reach AIOps
AIMS is a platform specifically tailored for enterprises that want quick time-to-value and ROI when it comes to anomaly detection and observability. AIMS can be installed in a matter of hours and start monitoring the infrastructure across the stack for anomalies and deviating patterns.
AIMS initially started as a scientific research project at the University Of Oslo and has in the past years seen big commercial success with well-renowned multinationals using the platform. The platform utilizes it’s own and proprietary algorithms developed by industry-leading data scientists.
Thanks to AIMS, enterprises can easily tap into over 200 different technologies and telemetry data sources to generate anomalies, service topologies and behavioral reports in real-time. The platform’s ultimate goal is to provide the next level of observability in a user-friendly and low-code approach – cutting time-to-value and increasing ROI.
A partnership of strategic value
The partnership between AIMS Innovation and Einar & Partners is unique in the market and of strategic value. With in-depth industry expertise in AIOps, both firms will offer a combined approach to get started with AIOps faster than with any other platform in the market.
Einar & Partners will deliver a special ServiceNow integration between the AIMS platform and ServiceNow ITSM & ITOM. The integration aims to enrich and complement the ServiceNow platform with anomaly incidents, anomaly alerts and CMDB data from AIMS.
Furthermore, Einar & Partners will facilitate stand-alone rollouts and implementation expertise of the AIMS platform towards customers around EU. With Einar & Partners’ strategic mindset in combination with the technology from AIMS Innovation – the partnership represents a synergy difficult to find elsewhere.
Below are some comments from the leadership team.
“We’re very excited about this partnership. The intellectual property and scientific background of AIMS align very well with the philosophy we have – to always push the limits of what AIOps can do. We’ve seen evidence of this platform truly can scale in enterprises and we’re excited about the integration possibilities to other platforms.”
Alexander Ljungström, Managing Director @ E&P
“At AIMS we have invested for years in scientific research and development of the AIMS platform. We have patiently been waiting for the AIOps market to mature. Our mission is to make AIOps affordable and available for any organization of any size. This is a fundamental belief shared with Einar & Partners. Bringing our unique technology to market requires working with the best and the most innovative in the AIOps eco-system globally – and that Einar & Partners represent.”
How does the optimal ServiceNow ITOM roadmap look after implementing discovery and CMDB? A simple enough question but with many possible answers and factors to consider.
Many are aware of the ServiceNow portfolio and what the possibilities in ITOM are. Yet few people know how to intelligently leverage the different ITOM modules for optimizing time-to-value, speed of implementation and ROI when moving beyond discovery.
Based on over 40 implementations of ITOM and industry leading experience, Einar & Partners together with iTSM Group is providing an in-depth session for platform owners, architects and decision makers interested in optimizing their ServiceNow ITOM journey.
In our webinar you’ll learn what really matters when moving beyond discovery; avoiding common pitfalls, boosting ROI and tackling organizational obstacles behind each decision. This will directly help to make educated decisions based on real experience that cut’s implementation time and saves budget.
Platform owners, budget makers or technical architects interested in learning the bigger picture and realistic efforts behind each ITOM module to create successful models for rolling out ITOM.
What do we promise?
This is not your average sales-pitch or “scratching-the-surface” webinar. Our webinar is pure knowledge condensed in 60 minutes – covering both technical and organizational aspects.
Why should I listen?
To get an insight into realistic implementation time, ROI, organizational challenges and technical pitfalls not mentioned in the product documentation for ITOM. Ultimately allowing you to create a fact-based and successful model to move beyond discovery.
Pre-requisites?
We assume any attendees are already familiarized with the concept of ServiceNow discovery and what it does. If not click here to read more.
Presenters
Alexander Ljungstrom, Managing Director & ITOM enthusiast @ Einar & Partners.
“Having previously worked in the ITOM team at ServiceNow, leading the ITOM BU at Fujitsu and now days the forefront at Einar & Partners – Alexander have helped over 40 organizations transformed with ITOM & the ServiceNow platform.”
Fabian Kunzke, AIOps & ITOM Lead @ iTSM Group
“Fabian is the AIOps & ITOM lead at iTSM Group. With great technical experience in multiple large-sized ITOM rollouts, and avid community contributor, he gives a strong innovative and sharp technical view on the ITOM journey. “
Einar & Partners are happy to announce the major news that we’re entering a strategic partnership with ITSM Group – a ServiceNow elite partner in the DACH region. ITSM Group is veterans in the German-speaking market in regards to digital transformation, enterprise service management, and organizational transformation.
Approaching the market in DACH
Jointly approaching the market in D-A-CH, the partnership aims to launch successful AIOps- & ITOM transformations to drive innovation at scale around the region.
Combining both companies’ forces and innovative nature into one mutual approach creates leading quality in the german-speaking market for ServiceNow ITOM & AIOps; difficult to find somewhere else.
Together the two companies will be at the forefront of ITOM, helping clients in the region from a strategic, organizational and technical perspective.
The specialized competence from Einar & Partners, and their successful strategies around ITOM programs, with the local expertise and in-depth knowledge at ITSM Group – form a winning alliance.
Our view on the partnership
Alexander Ljungstrom, Managing Director at Einar & Partners describes his view on the partnership.
“We’re extremely pleased with the partnership, entering 2021 together as a joint force in DACH. With special competence in DevOps, and resources with the technical know-how in ServiceNow ITOM – ITSM Group was the natural choice for us.”
Alexander Ljungstrom, Managing Director @ E&P
Fabian Kunzke, AIOps & ITOM Lead at ITSM Group comments on the partnership below.
“We’re equally excited to enter this new partnership in 2021. The reputation and in-depth strategic expertise at Einar & Partners is rock-solid and creates fantastic synergies between our companies and resources.”
Fabian Kunzke, AIOps & ITOM Lead @ ITSM Group
Amsterdam, 15/12/2020 - 08:00 CET
Further Information
iTSM Group Siegfried Riedel Am Kuemmerling 21-25 D-55294 Bodenheim Phone: + 49 61 35 93 34 0 info[at]itsmgroup.com https://www.itsmgroup.com/
Further Information
Einar & Partners Alexander Ljungström Herengracht 420 1017BZ, Amsterdam Phone: +31 6 146 55 199 ping[at]einar.partners https://einar.partners/
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok