The release notes of the latest ServiceNow version is out in public and this time we’re going all the way to Rome. The new release is packed with improvements, additions and developments in the ITOM parts of the platform. In this article by Einar & Partners we give you all the important highlights and news in ServiceNow ITOM for the Rome release.
Site Reliability Metrics for SRE’s and Ops
Site Reliability Operations, or SRO – is a product by ServiceNow created specifically for SRE teams that are working heavily with microservices and site reliability engineering. In the Rome Release, the SRO product is being improved additionally with Site Reliability Metrics. Engineers and operations teams that are working with site reliability engineering can now see performance, error budgets, indicators and service level objectives. All within one workspace.
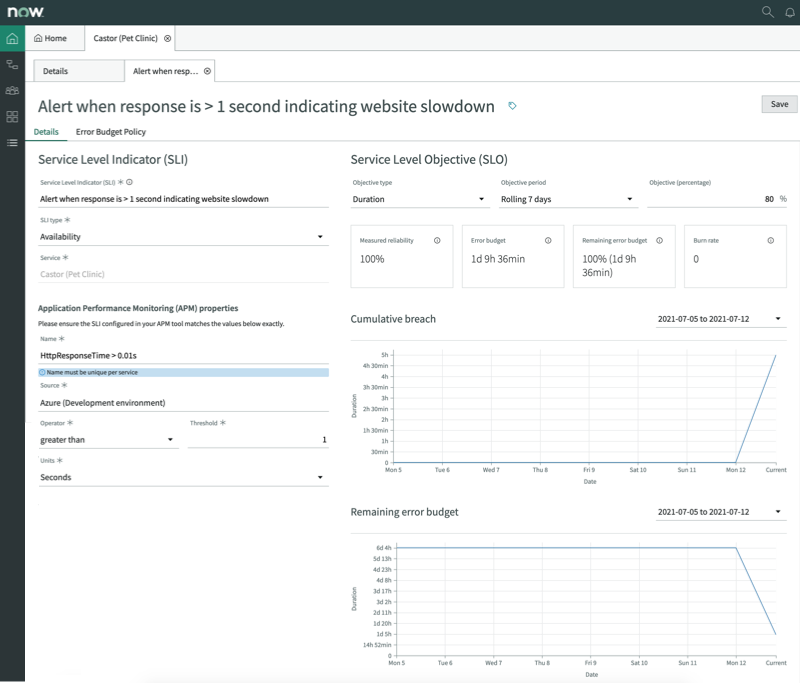
This is a welcome addition to the previously rather lightweight SRO application. It also demonstrates that ServiceNow is more serious than ever to develop their positioning towards cutting edge DevOps and containerized practices.
Containerized MID-servers
Speaking of containerized practices, the MID-server is now officially put into a docker image and available to be pushed out as a container based application. This has already existed for a while, although not supported officially by ServiceNow – until now that is. In practice this means that the MID server capacity and sizing can be scaled and sized very easily depending on load and anticipated activity (for example, discovery).
At the time of this article being written, IntegrationHub and Orchestration is not (officially) supported when using containerized MID-server docker images.
Agent Client Collector – agent based discovery
The agent client collector (ACC) is officially released in its full capacity in Rome, and is starting to become quite the mature alternative to agentless discovery. The agent based discovery in ServiceNow solves the long-standing challenge of having to provide credentials and opening firewalls across the infrastructure. When using the agent based discovery, customers should still be aware that products such as service mapping is not yet supported.
Nonetheless, agent based discovery is perfectly suited for endpoints, laptops and infrastructure where agentless discovery is not permitted.
For more information about the ACC-V framework, check out our video below.
More sources for Health Log Analytics
Health Log Analytics, originating from the acquisition of Loom Systems roughly 2 years ago, has now matured to a strong core-piece of the ServiceNow AIOps portfolio. In the latest release the Health Log Analytics product supports a whole bunch of new sources for ingesting log data, such as:
- Amazon CloudWatch
- Amazon S3
- Microsoft Azure Log Analytics
- Microsoft Azure Event Hubs
- Apache Kafka
- REST API, for streaming your log data to the instance in JSON format
Event Management news
For Event Management it is now possible to integrate Grafana events out of the box and plugin directly to the Event Management engine in ServiceNow. Additionally, ServiceNow has added support for EIF format (Event Integration Facility). It might sounds obscure, but this format is the de-facto standard format for a lot of IBM products. With the closer relationship between ServiceNow and IBM, this will save a lot of headache when integrating technologies such as IBM Tivoli and the corresponding monitoring agents.
Oracle Cloud Discovery – official support
Oracle Cloud can now fully be discovered by ServiceNow Cloud Discovery. Previously only available as an app to the ServiceNow App store, it is now fully integrated in the core part of Discovery. This means that cloud resources that customers have in oracle cloud can now be real-time refreshed and included in the CMDB with a very simple connection.
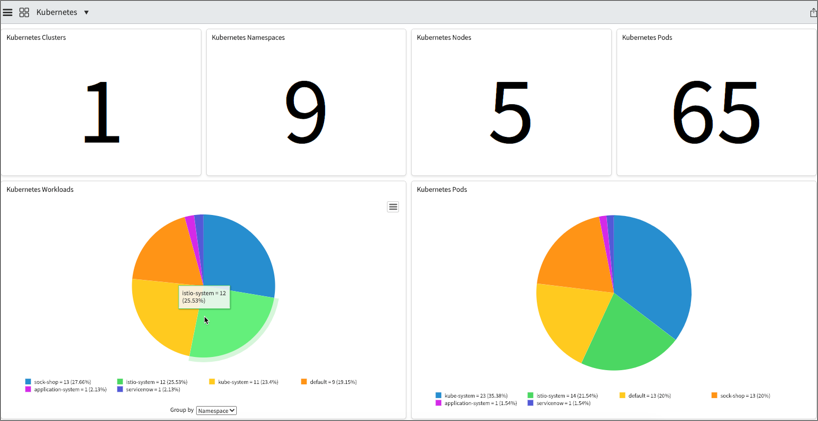
Kubernetes and cloud components in Service Maps
For organizations that are using tag based service mapping, the latest release will make a big difference. Previously every resource that needed to show up in a tag-based service map also needed a tag. Although this principle makes sense from a logical standpoint, in containerized environments, not every pod and component is tagged.
In the Rome release Kubernetes and cloud components can now be automatically be included based on their relationships. In other words, you just need to have the parent tagged in order to include children.
Tag Governance – a new application
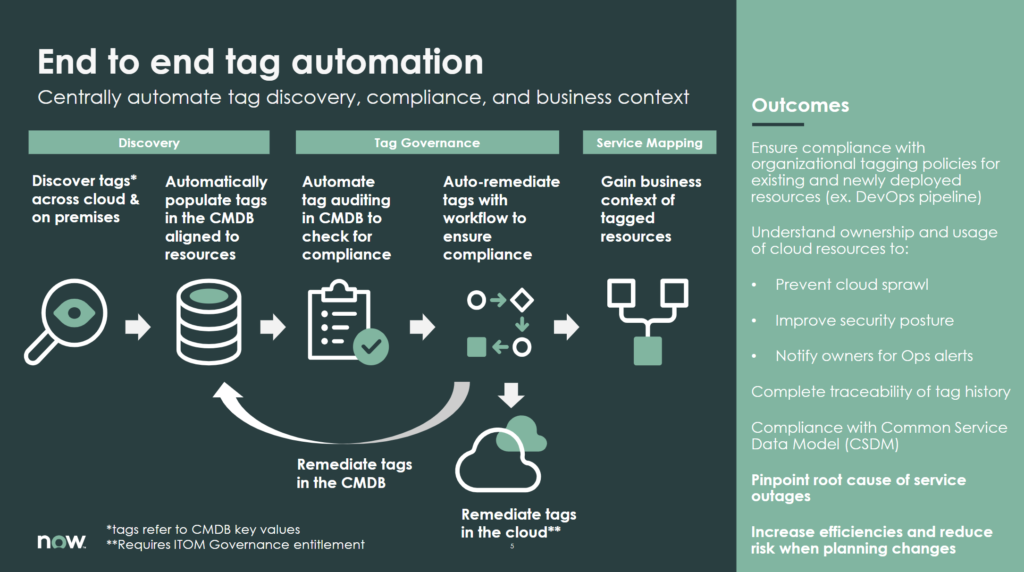
Keeping track of tags in ServiceNow have already been possible for a few releases. But with the latest release, the capability have been lifted to entirely new levels. This is perhaps the most exciting product in the Rome release in our opinion.
With the new tag governance application, tags can be tracked, certified and kept up-to-date through workflows and rulesets. But perhaps more importantly, any tags that are found not be compliant with the defined rules can be remediated. In other words, ServiceNow can correct tags in Azure, AWS and other cloud platforms.
A single pane of glass to keep track for the tagging across multiple clouds and applying smart workflow logic. Isn’t that what we love about this platform?
Read more in the official community post here.
Summary and final thoughts
As we can see each release continues to be packed with additions to the ITOM portfolio. It appears like ServiceNow is pushing with full force towards keeping control, visibility and compliance on cloud resources and modern architectures (containers, serverless).
Additionally, in the latest release we also see evidence of just how serious ServiceNow are about bridging in to the space of observability and site reliability engineering. With the recent acquisition of Lightstep, a DevOps observability platform, ServiceNow chooses to strategically position themselves towards the modern era of IT Operations more and more.
Exciting times!